Fast Growth Rates for Time Series and Panel Data
fgrowth.Rdfgrowth is a S3 generic to compute (sequences of) suitably lagged / leaded, iterated and compounded growth rates, obtained with via the exact method of computation or through log differencing. By default growth rates are provided in percentage terms, but any scale factor can be applied. The growth operator G is a parsimonious wrapper around fgrowth, and also provides more flexibility when applied to data frames.
Usage
fgrowth(x, n = 1, diff = 1, ...)
G(x, n = 1, diff = 1, ...)
# Default S3 method
fgrowth(x, n = 1, diff = 1, g = NULL, t = NULL, fill = NA,
logdiff = FALSE, scale = 100, power = 1, stubs = TRUE, ...)
# Default S3 method
G(x, n = 1, diff = 1, g = NULL, t = NULL, fill = NA, logdiff = FALSE,
scale = 100, power = 1, stubs = .op[["stub"]], ...)
# S3 method for class 'matrix'
fgrowth(x, n = 1, diff = 1, g = NULL, t = NULL, fill = NA,
logdiff = FALSE, scale = 100, power = 1,
stubs = length(n) + length(diff) > 2L, ...)
# S3 method for class 'matrix'
G(x, n = 1, diff = 1, g = NULL, t = NULL, fill = NA, logdiff = FALSE,
scale = 100, power = 1, stubs = .op[["stub"]], ...)
# S3 method for class 'data.frame'
fgrowth(x, n = 1, diff = 1, g = NULL, t = NULL, fill = NA,
logdiff = FALSE, scale = 100, power = 1,
stubs = length(n) + length(diff) > 2L, ...)
# S3 method for class 'data.frame'
G(x, n = 1, diff = 1, by = NULL, t = NULL, cols = is.numeric,
fill = NA, logdiff = FALSE, scale = 100, power = 1, stubs = .op[["stub"]],
keep.ids = TRUE, ...)
# Methods for indexed data / compatibility with plm:
# S3 method for class 'pseries'
fgrowth(x, n = 1, diff = 1, fill = NA, logdiff = FALSE, scale = 100,
power = 1, stubs = length(n) + length(diff) > 2L, shift = "time", ...)
# S3 method for class 'pseries'
G(x, n = 1, diff = 1, fill = NA, logdiff = FALSE, scale = 100,
power = 1, stubs = .op[["stub"]], shift = "time", ...)
# S3 method for class 'pdata.frame'
fgrowth(x, n = 1, diff = 1, fill = NA, logdiff = FALSE, scale = 100,
power = 1, stubs = length(n) + length(diff) > 2L, shift = "time", ...)
# S3 method for class 'pdata.frame'
G(x, n = 1, diff = 1, cols = is.numeric, fill = NA, logdiff = FALSE,
scale = 100, power = 1, stubs = .op[["stub"]], shift = "time", keep.ids = TRUE, ...)
# Methods for grouped data frame / compatibility with dplyr:
# S3 method for class 'grouped_df'
fgrowth(x, n = 1, diff = 1, t = NULL, fill = NA, logdiff = FALSE,
scale = 100, power = 1, stubs = length(n) + length(diff) > 2L,
keep.ids = TRUE, ...)
# S3 method for class 'grouped_df'
G(x, n = 1, diff = 1, t = NULL, fill = NA, logdiff = FALSE,
scale = 100, power = 1, stubs = .op[["stub"]], keep.ids = TRUE, ...)Arguments
- x
a numeric vector / time series, (time series) matrix, data frame, 'indexed_series' ('pseries'), 'indexed_frame' ('pdata.frame') or grouped data frame ('grouped_df').
- n
integer. A vector indicating the number of lags or leads.
- diff
integer. A vector of integers > 1 indicating the order of taking growth rates, e.g.
diff = 2means computing the growth rate of the growth rate.- g
a factor,
GRPobject, or atomic vector / list of vectors (internally grouped withgroup) used to groupx. Note that withoutt, all values in a group need to be consecutive and in the right order. See Details offlag.- by
data.frame method: Same as
g, but also allows one- or two-sided formulas i.e.~ group1orvar1 + var2 ~ group1 + group2. See Examples.- t
a time vector or list of vectors. See
flag.- cols
data.frame method: Select columns to compute growth rates using a function, column names, indices or a logical vector. Default: All numeric variables. Note:
colsis ignored if a two-sided formula is passed toby.- fill
value to insert when vectors are shifted. Default is
NA.- logdiff
logical. Compute log-difference growth rates instead of exact growth rates. See Details.
- scale
logical. Scale factor post-applied to growth rates, default is 100 which gives growth rates in percentage terms. See Details.
- power
numeric. Apply a power to annualize or compound growth rates e.g.
fgrowth(AirPassengers, 12, power = 1/12)is equivalent to((AirPassengers/flag(AirPassengers, 12))^(1/12)-1)*100.- stubs
logical.
TRUE(default) will rename all computed columns by adding a prefix "LnGdiff." / "FnGdiff.", or "LnDlogdiff." / "FnDlogdiff." iflogdiff = TRUE.- shift
pseries / pdata.frame methods: character.
"time"or"row". Seeflagfor details.- keep.ids
data.frame / pdata.frame / grouped_df methods: Logical. Drop all identifiers from the output (which includes all variables passed to
byortusing formulas). Note: For 'grouped_df' / 'pdata.frame' identifiers are dropped, but the"groups"/"index"attributes are kept.- ...
arguments to be passed to or from other methods.
Details
fgrowth/G by default computes exact growth rates using repeat(diff) ((x[i]/x[i-n])^power - 1)*scale, so for diff > 1 it computes growth rate of growth rates. If logdiff = TRUE, approximate growth rates are computed using log(x[i]/x[i-n])*scale for diff = 1 and repeat(diff-1) x[i] - x[i-n] thereafter (usually diff = 1 for log-differencing). For further details see the help pages of fdiff and flag.
Value
x where the growth rate was taken diff times using lags n of itself, scaled by scale. Computations can be grouped by g/by and/or ordered by t. See Details and Examples.
Examples
## Simple Time Series: AirPassengers
G(AirPassengers) # Growth rate, same as fgrowth(AirPassengers)
#> Jan Feb Mar Apr May Jun
#> 1949 NA 5.3571429 11.8644068 -2.2727273 -6.2015504 11.5702479
#> 1950 -2.5423729 9.5652174 11.9047619 -4.2553191 -7.4074074 19.2000000
#> 1951 3.5714286 3.4482759 18.6666667 -8.4269663 5.5214724 3.4883721
#> 1952 3.0120482 5.2631579 7.2222222 -6.2176166 1.1049724 19.1256831
#> 1953 1.0309278 0.0000000 20.4081633 -0.4237288 -2.5531915 6.1135371
#> Jul Aug Sep Oct Nov Dec
#> 1949 9.6296296 0.0000000 -8.1081081 -12.5000000 -12.6050420 13.4615385
#> 1950 14.0939597 0.0000000 -7.0588235 -15.8227848 -14.2857143 22.8070175
#> 1951 11.7977528 0.0000000 -7.5376884 -11.9565217 -9.8765432 13.6986301
#> 1952 5.5045872 5.2173913 -13.6363636 -8.6124402 -9.9476440 12.7906977
#> 1953 8.6419753 3.0303030 -12.8676471 -10.9704641 -14.6919431 11.6666667
#> [ reached 'max' / getOption("max.print") -- omitted 7 rows ]
G(AirPassengers, logdiff = TRUE) # Log-difference
#> Jan Feb Mar Apr May Jun
#> 1949 NA 5.2185753 11.2117298 -2.2989518 -6.4021859 10.9484233
#> 1950 -2.5752496 9.1349779 11.2477983 -4.3485112 -7.6961041 17.5632569
#> 1951 3.5091320 3.3901552 17.1148256 -8.8033349 5.3744276 3.4289073
#> 1952 2.9675768 5.1293294 6.9733338 -6.4193158 1.0989122 17.5008910
#> 1953 1.0256500 0.0000000 18.5717146 -0.4246291 -2.5863511 5.9339440
#> Jul Aug Sep Oct Nov Dec
#> 1949 9.1937495 0.0000000 -8.4557388 -13.3531393 -13.4732594 12.6293725
#> 1950 13.1852131 0.0000000 -7.3203404 -17.2245905 -15.4150680 20.5443974
#> 1951 11.1521274 0.0000000 -7.8369067 -12.7339422 -10.3989714 12.8381167
#> 1952 5.3584246 5.0858417 -14.6603474 -9.0060824 -10.4778951 12.0363682
#> 1953 8.2887660 2.9852963 -13.7741925 -11.6202008 -15.8901283 11.0348057
#> [ reached 'max' / getOption("max.print") -- omitted 7 rows ]
G(AirPassengers, 1, 2) # Growth rate of growth rate
#> Jan Feb Mar Apr May
#> 1949 NA NA 121.4689266 -119.1558442 172.8682171
#> 1950 -118.8861985 -476.2318841 24.4588745 -135.7446809 74.0740741
#> 1951 -84.3406593 -3.4482759 441.3333333 -145.1444623 -165.5214724
#> 1952 -78.0120482 74.7368421 37.2222222 -186.0900757 -117.7716390
#> 1953 -91.9400187 -100.0000000 Inf -102.0762712 502.5531915
#> Jun Jul Aug Sep Oct
#> 1949 -286.5702479 -16.7724868 -100.0000000 -Inf 54.1666667
#> 1950 -359.2000000 -26.5939597 -100.0000000 -Inf 124.1561181
#> 1951 -36.8217054 238.2022472 -100.0000000 -Inf 58.6231884
#> 1952 1630.8743169 -71.2188729 -5.2173913 -361.3636364 -36.8421053
#> 1953 -339.4468705 41.3580247 -64.9350649 -524.6323529 -14.7438216
#> Nov Dec
#> 1949 0.8403361 -206.7948718
#> 1950 -9.7142857 -259.6491228
#> 1951 -17.3961841 -238.6986301
#> 1952 15.5031995 -228.5801714
#> 1953 33.9227124 -179.4086022
#> [ reached 'max' / getOption("max.print") -- omitted 7 rows ]
G(AirPassengers, 12) # Seasonal growth rate (data is monthly)
#> Jan Feb Mar Apr May Jun
#> 1949 NA NA NA NA NA NA
#> 1950 2.6785714 6.7796610 6.8181818 4.6511628 3.3057851 10.3703704
#> 1951 26.0869565 19.0476190 26.2411348 20.7407407 37.6000000 19.4630872
#> 1952 17.9310345 20.0000000 8.4269663 11.0429448 6.3953488 22.4719101
#> 1953 14.6198830 8.8888889 22.2797927 29.8342541 25.1366120 11.4678899
#> Jul Aug Sep Oct Nov Dec
#> 1949 NA NA NA NA NA NA
#> 1950 14.8648649 14.8648649 16.1764706 11.7647059 9.6153846 18.6440678
#> 1951 17.0588235 17.0588235 16.4556962 21.8045113 28.0701754 18.5714286
#> 1952 15.5778894 21.6080402 13.5869565 17.9012346 17.8082192 16.8674699
#> 1953 14.7826087 12.3966942 13.3971292 10.4712042 4.6511628 3.6082474
#> [ reached 'max' / getOption("max.print") -- omitted 7 rows ]
head(G(AirPassengers, -2:2, 1:3)) # Sequence of leaded/lagged and iterated growth rates
#> F2G1 F2G2 F2G3 FG1 FG2 FG3 --
#> Jan 1949 -15.151515 -266.66667 77.97753 -5.084746 -52.05811 -90.63805 112
#> Feb 1949 -8.527132 91.86047 -285.94592 -10.606061 -556.06061 757.77959 118
#> Mar 1949 9.090909 -149.83165 -51.15620 2.325581 -64.82558 -60.41293 132
#> Apr 1949 -4.444444 -49.40171 -63.68691 6.611570 -163.75443 -1006.58997 129
#> May 1949 -18.243243 -306.75676 330.09195 -10.370370 18.06268 NaN 121
#> G1 G2 G3 L2G1 L2G2 L2G3
#> Jan 1949 NA NA NA NA NA NA
#> Feb 1949 5.357143 NA NA NA NA NA
#> Mar 1949 11.864407 121.4689 NA 17.857143 NA NA
#> Apr 1949 -2.272727 -119.1558 -198.0957 9.322034 NA NA
#> May 1949 -6.201550 172.8682 -245.0774 -8.333333 -146.66667 NA
#> [ reached 'max' / getOption("max.print") -- omitted 1 row ]
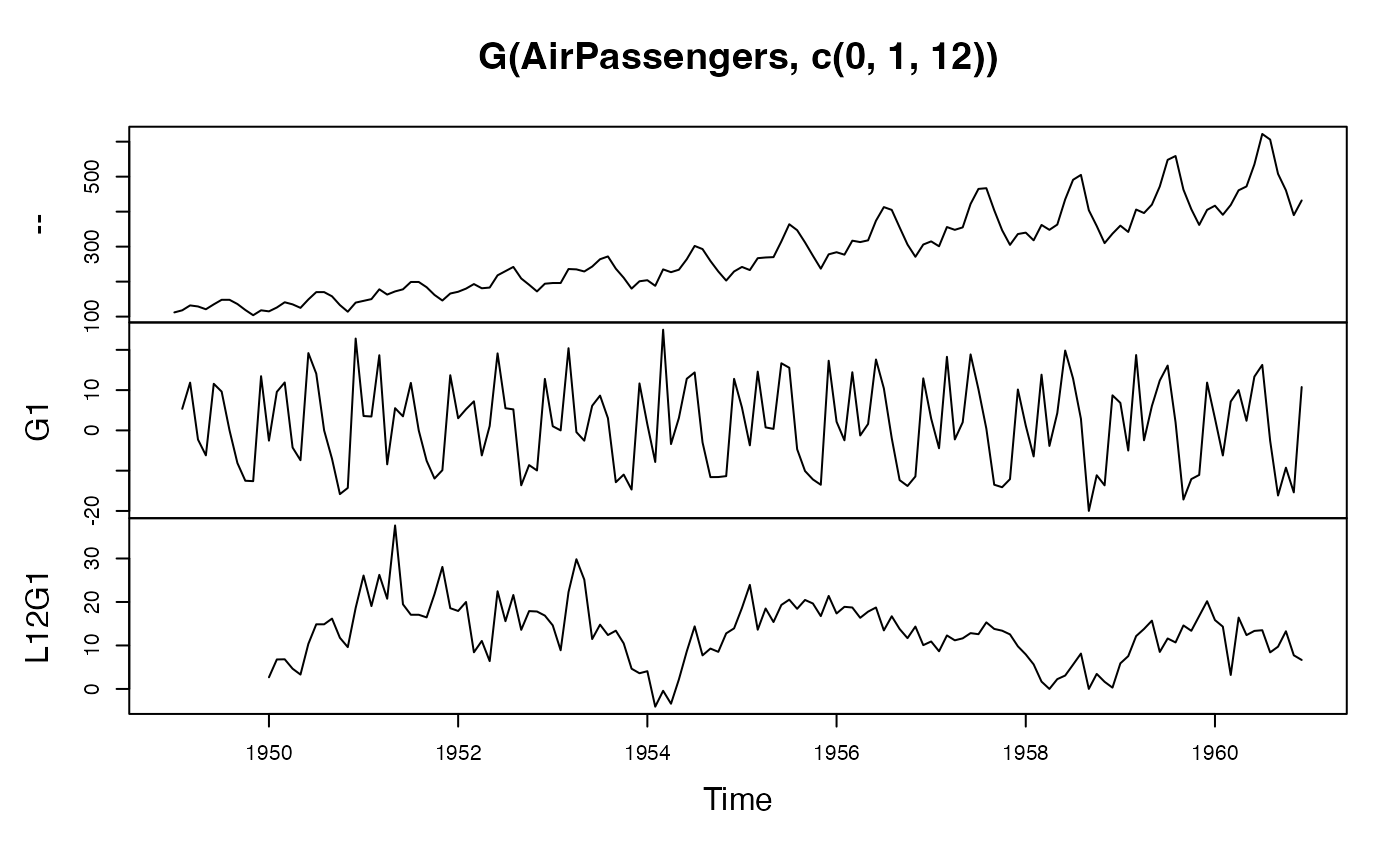
# let's do some visual analysis
plot(G(AirPassengers, c(0, 1, 12)))
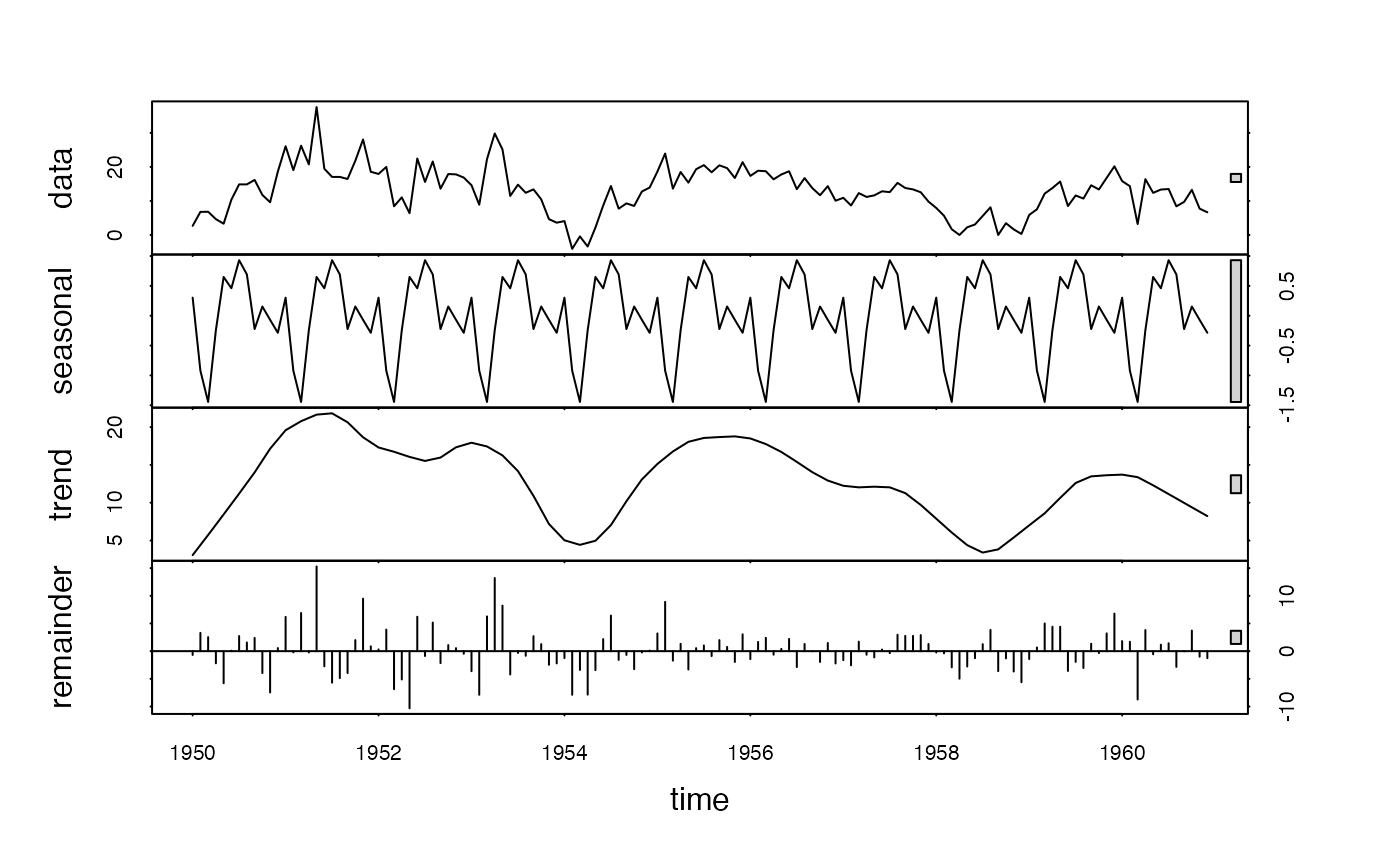
 plot(stl(window(G(AirPassengers, 12), # Taking seasonal growth rate removes most seasonal variation
1950), "periodic"))
plot(stl(window(G(AirPassengers, 12), # Taking seasonal growth rate removes most seasonal variation
1950), "periodic"))
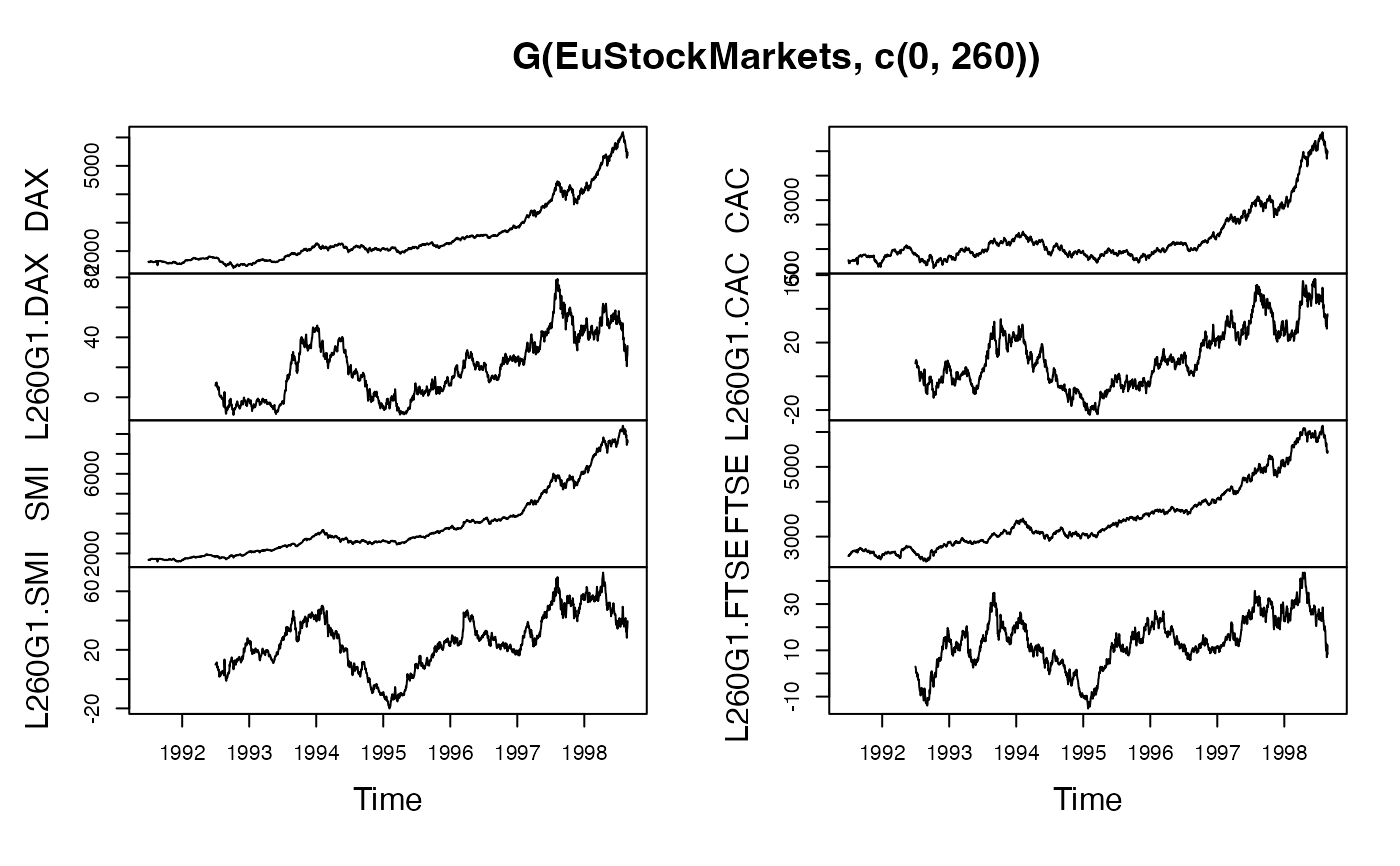
 ## Time Series Matrix of 4 EU Stock Market Indicators, recorded 260 days per year
plot(G(EuStockMarkets,c(0,260))) # Plot series and annual growth rates
## Time Series Matrix of 4 EU Stock Market Indicators, recorded 260 days per year
plot(G(EuStockMarkets,c(0,260))) # Plot series and annual growth rates
 summary(lm(L260G1.DAX ~., G(EuStockMarkets,260))) # Annual growth rate of DAX regressed on the
#>
#> Call:
#> lm(formula = L260G1.DAX ~ ., data = G(EuStockMarkets, 260))
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -19.5094 -4.7763 0.4586 5.0337 18.2316
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 4.48795 0.38357 11.70 < 2e-16 ***
#> L260G1.SMI 0.37048 0.02635 14.06 < 2e-16 ***
#> L260G1.CAC 0.82319 0.02092 39.34 < 2e-16 ***
#> L260G1.FTSE -0.25008 0.03883 -6.44 1.58e-10 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 7.817 on 1596 degrees of freedom
#> (260 observations deleted due to missingness)
#> Multiple R-squared: 0.8585, Adjusted R-squared: 0.8582
#> F-statistic: 3226 on 3 and 1596 DF, p-value: < 2.2e-16
#>
# growth rates of the other indicators
## World Development Panel Data
head(fgrowth(num_vars(wlddev), 1, 1, # Computes growth rates of numeric variables
wlddev$country, wlddev$year)) # fgrowth requires external inputs..
#> year decade PCGDP LIFEEX GINI ODA POP
#> 1 NA NA NA NA NA NA NA
#> 2 0.05102041 0 NA 1.590335 NA 98.74969 1.916611
#> 3 0.05099439 0 NA 1.544202 NA -51.37884 1.985199
#> 4 0.05096840 0 NA 1.493830 NA 110.66998 2.050636
#> 5 0.05094244 0 NA 1.448294 NA 24.48259 2.112246
#> 6 0.05091650 0 NA 1.407306 NA 15.51770 2.170793
head(G(wlddev, 1, 1, ~country, ~year)) # Growth of numeric variables, id's attached
#> country year G1.decade G1.PCGDP G1.LIFEEX G1.GINI G1.ODA G1.POP
#> 1 Afghanistan 1960 NA NA NA NA NA NA
#> 2 Afghanistan 1961 0 NA 1.590335 NA 98.74969 1.916611
#> 3 Afghanistan 1962 0 NA 1.544202 NA -51.37884 1.985199
#> 4 Afghanistan 1963 0 NA 1.493830 NA 110.66998 2.050636
#> 5 Afghanistan 1964 0 NA 1.448294 NA 24.48259 2.112246
#> 6 Afghanistan 1965 0 NA 1.407306 NA 15.51770 2.170793
head(G(wlddev, 1, 1, ~country)) # Without t: Works because data is ordered
#> country G1.year G1.decade G1.PCGDP G1.LIFEEX G1.GINI G1.ODA
#> 1 Afghanistan NA NA NA NA NA NA
#> 2 Afghanistan 0.05102041 0 NA 1.590335 NA 98.74969
#> 3 Afghanistan 0.05099439 0 NA 1.544202 NA -51.37884
#> 4 Afghanistan 0.05096840 0 NA 1.493830 NA 110.66998
#> 5 Afghanistan 0.05094244 0 NA 1.448294 NA 24.48259
#> 6 Afghanistan 0.05091650 0 NA 1.407306 NA 15.51770
#> G1.POP
#> 1 NA
#> 2 1.916611
#> 3 1.985199
#> 4 2.050636
#> 5 2.112246
#> 6 2.170793
head(G(wlddev, 1, 1, PCGDP + LIFEEX ~ country, ~year)) # Growth of GDP per Capita & Life Expectancy
#> country year G1.PCGDP G1.LIFEEX
#> 1 Afghanistan 1960 NA NA
#> 2 Afghanistan 1961 NA 1.590335
#> 3 Afghanistan 1962 NA 1.544202
#> 4 Afghanistan 1963 NA 1.493830
#> 5 Afghanistan 1964 NA 1.448294
#> 6 Afghanistan 1965 NA 1.407306
head(G(wlddev, 0:1, 1, ~ country, ~year, cols = 9:10)) # Same, also retaining original series
#> country year PCGDP G1.PCGDP LIFEEX G1.LIFEEX
#> 1 Afghanistan 1960 NA NA 32.446 NA
#> 2 Afghanistan 1961 NA NA 32.962 1.590335
#> 3 Afghanistan 1962 NA NA 33.471 1.544202
#> 4 Afghanistan 1963 NA NA 33.971 1.493830
#> 5 Afghanistan 1964 NA NA 34.463 1.448294
#> 6 Afghanistan 1965 NA NA 34.948 1.407306
head(G(wlddev, 0:1, 1, ~ country, ~year, 9:10, # Dropping id columns
keep.ids = FALSE))
#> PCGDP G1.PCGDP LIFEEX G1.LIFEEX
#> 1 NA NA 32.446 NA
#> 2 NA NA 32.962 1.590335
#> 3 NA NA 33.471 1.544202
#> 4 NA NA 33.971 1.493830
#> 5 NA NA 34.463 1.448294
#> 6 NA NA 34.948 1.407306
summary(lm(L260G1.DAX ~., G(EuStockMarkets,260))) # Annual growth rate of DAX regressed on the
#>
#> Call:
#> lm(formula = L260G1.DAX ~ ., data = G(EuStockMarkets, 260))
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -19.5094 -4.7763 0.4586 5.0337 18.2316
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 4.48795 0.38357 11.70 < 2e-16 ***
#> L260G1.SMI 0.37048 0.02635 14.06 < 2e-16 ***
#> L260G1.CAC 0.82319 0.02092 39.34 < 2e-16 ***
#> L260G1.FTSE -0.25008 0.03883 -6.44 1.58e-10 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 7.817 on 1596 degrees of freedom
#> (260 observations deleted due to missingness)
#> Multiple R-squared: 0.8585, Adjusted R-squared: 0.8582
#> F-statistic: 3226 on 3 and 1596 DF, p-value: < 2.2e-16
#>
# growth rates of the other indicators
## World Development Panel Data
head(fgrowth(num_vars(wlddev), 1, 1, # Computes growth rates of numeric variables
wlddev$country, wlddev$year)) # fgrowth requires external inputs..
#> year decade PCGDP LIFEEX GINI ODA POP
#> 1 NA NA NA NA NA NA NA
#> 2 0.05102041 0 NA 1.590335 NA 98.74969 1.916611
#> 3 0.05099439 0 NA 1.544202 NA -51.37884 1.985199
#> 4 0.05096840 0 NA 1.493830 NA 110.66998 2.050636
#> 5 0.05094244 0 NA 1.448294 NA 24.48259 2.112246
#> 6 0.05091650 0 NA 1.407306 NA 15.51770 2.170793
head(G(wlddev, 1, 1, ~country, ~year)) # Growth of numeric variables, id's attached
#> country year G1.decade G1.PCGDP G1.LIFEEX G1.GINI G1.ODA G1.POP
#> 1 Afghanistan 1960 NA NA NA NA NA NA
#> 2 Afghanistan 1961 0 NA 1.590335 NA 98.74969 1.916611
#> 3 Afghanistan 1962 0 NA 1.544202 NA -51.37884 1.985199
#> 4 Afghanistan 1963 0 NA 1.493830 NA 110.66998 2.050636
#> 5 Afghanistan 1964 0 NA 1.448294 NA 24.48259 2.112246
#> 6 Afghanistan 1965 0 NA 1.407306 NA 15.51770 2.170793
head(G(wlddev, 1, 1, ~country)) # Without t: Works because data is ordered
#> country G1.year G1.decade G1.PCGDP G1.LIFEEX G1.GINI G1.ODA
#> 1 Afghanistan NA NA NA NA NA NA
#> 2 Afghanistan 0.05102041 0 NA 1.590335 NA 98.74969
#> 3 Afghanistan 0.05099439 0 NA 1.544202 NA -51.37884
#> 4 Afghanistan 0.05096840 0 NA 1.493830 NA 110.66998
#> 5 Afghanistan 0.05094244 0 NA 1.448294 NA 24.48259
#> 6 Afghanistan 0.05091650 0 NA 1.407306 NA 15.51770
#> G1.POP
#> 1 NA
#> 2 1.916611
#> 3 1.985199
#> 4 2.050636
#> 5 2.112246
#> 6 2.170793
head(G(wlddev, 1, 1, PCGDP + LIFEEX ~ country, ~year)) # Growth of GDP per Capita & Life Expectancy
#> country year G1.PCGDP G1.LIFEEX
#> 1 Afghanistan 1960 NA NA
#> 2 Afghanistan 1961 NA 1.590335
#> 3 Afghanistan 1962 NA 1.544202
#> 4 Afghanistan 1963 NA 1.493830
#> 5 Afghanistan 1964 NA 1.448294
#> 6 Afghanistan 1965 NA 1.407306
head(G(wlddev, 0:1, 1, ~ country, ~year, cols = 9:10)) # Same, also retaining original series
#> country year PCGDP G1.PCGDP LIFEEX G1.LIFEEX
#> 1 Afghanistan 1960 NA NA 32.446 NA
#> 2 Afghanistan 1961 NA NA 32.962 1.590335
#> 3 Afghanistan 1962 NA NA 33.471 1.544202
#> 4 Afghanistan 1963 NA NA 33.971 1.493830
#> 5 Afghanistan 1964 NA NA 34.463 1.448294
#> 6 Afghanistan 1965 NA NA 34.948 1.407306
head(G(wlddev, 0:1, 1, ~ country, ~year, 9:10, # Dropping id columns
keep.ids = FALSE))
#> PCGDP G1.PCGDP LIFEEX G1.LIFEEX
#> 1 NA NA 32.446 NA
#> 2 NA NA 32.962 1.590335
#> 3 NA NA 33.471 1.544202
#> 4 NA NA 33.971 1.493830
#> 5 NA NA 34.463 1.448294
#> 6 NA NA 34.948 1.407306